An introduction to the web feed client Newsboat
This article was originally included in the article “An introduction to web feeds”, but it turned out the be a bit too long so I split them up in two parts.
So. I’m pretty sure that it comes to no ones surprice that Newsboat is my web feed reader client of choice. If you happen to have missed out on this client, then you’re in for a treat! Newsboat is a feature rich text-based client that makes reading news more enjoyable.
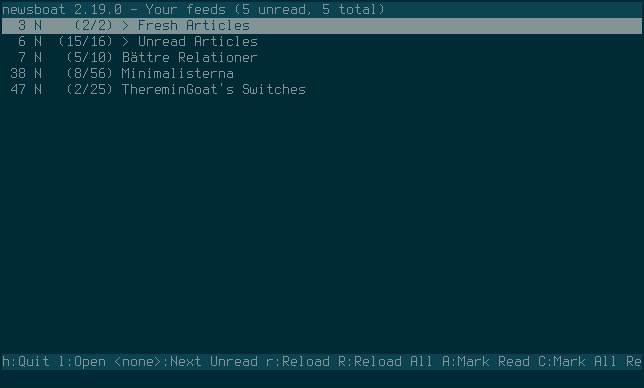
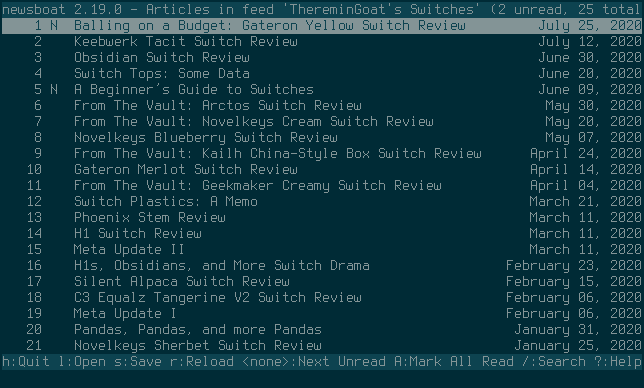
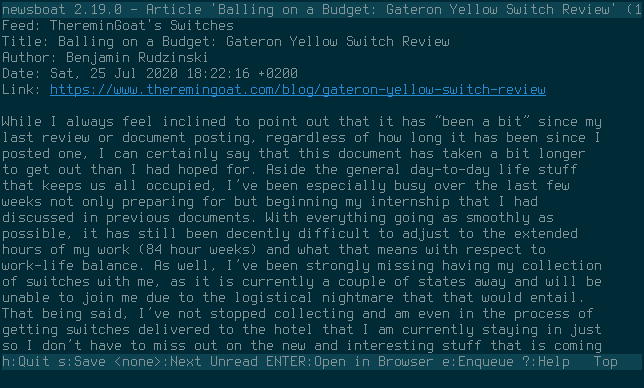
I like Newsboat for multiple reasons, some of them are because it’s a client that’s keyboard driven, highly customizable, has support for regular expression filters, macros, running multiple instances (at the same time with different settings/feeds!) and because it even let’s me execute shell scripts.
I have two different profiles of Newsboat with different settings and feeds to separate my regular news from my video content subscriptions, which mainly is YouTube, even though I have at least one channel from PeerTube now!
How to get started with Newsboat
After you have installed Newsboat you should probably tweak a few settings and add at least one feed before you run it for the first time. If you don’t you will be greeted with this message:
Error: no URLs configured. Please fill the file /home/<user>/.newsboat/urls with RSS feed URLs or import an OPML file.
Add your feed(s) to the file $HOME/.config/newsboat/urls (one feed per line):
http://hunden.linuxkompis.se/feed.xml
https://fosstodon.org/@hund.rss
It should be noted that Newsboat supports cloud based services like The Old Reader, NewsBlur, FeedHQ, Bazqux, Tiny Tiny RSS and nextCloud News. You can read more about that in the chapter “Newsboat as a Client for Newsreading Services”.
I also recommend changing the default browser to your browser of choice in the file $HOME/.config/newsboat/config?. For Firefox it would be something like:
browser "firefox --new-tab %u"
For a complete documentation about the configuration options check out their website. My current setup looks like this.
Filters
A basic ignore-filter that hides articles based on keywords in the title looks like this:
ignore-article "https://feber.se/rss" "title =~ \"<keyword>|<another keyword>\""
It’s also possible to filter articles based on keywords from the link, author, content, date, age and so on. It can actually get quite advanced if you would like to.
It’s also possible to create dynamic feeds based on certain filters. One examples would be to list all unread articles in one feed:
"query:> \Fresh Articles:age < \"1\" and title !~ \"trailers|trailer|\" and link !~ \"r\/gentoo\""
Another one would be to only show articles newer than N days. In this example it will only show articles that’s 48 hours old or newer:
"query:> \Fresh Articles:age < \"2\" and unread = \"yes\""
It’s also possible to combine multiple filters with each other. In this example I created a dynamic feed that only lists unread articles that has the keyword “trailer” in the title:
"query:> \Trailers:unread =\"yes\" and title =~ \"trailer\""
You can read more about filters in their documentation.
Macros
Macros is another feature that I really like about Newsboat. Even though I might only use some basic macros myself, I find them valuable.
I use mainly three macros. One that lets me open the article in my readability-script:
macro r set browser "html2text.py %u | fold -s -w 115 | less" ; open-in-browser ; set browser "`echo $BROWSER`"
Another one that opens the article in Firefox via its reader view mode:
macro R set browser "firefox --new-tab about:reader?url=%u" ; open-in-browser ; set browser "`echo $BROWSER`"
And a third one that opens the articles (with videos) in my media player:
macro m set browser "mpv %u" ; open-in-browser ; set browser "`echo $BROWSER`"
You run a macro with the key , followed by the key you assigned the macro to. You can read more about macros here.
How my readability script works
With the help of my good friend Ghosty, I managed to create a Python-script that fetches the articles and presents them to me in a more readable way. I use this script when the feed only publish an excerpt and not the whole article.
Here’s what some articles looks like when they want to force you to their websites:

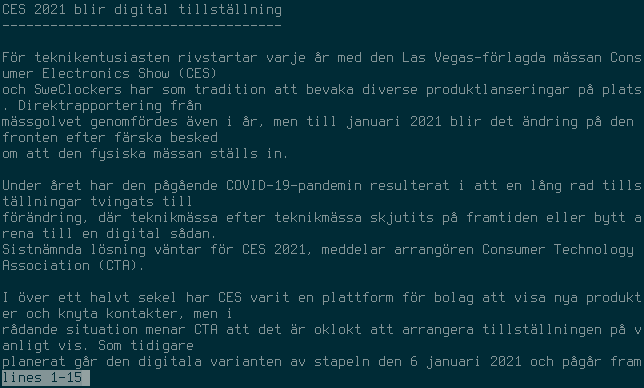
It works pretty much flawlessly, except for one little detail; there’s no images. If the article includes images I have no way of knowing it.
A workaround to this issue for me was to involve another web browser. I happen to have Firefox installed for websites that I don’t really trust. When I come across a image heavy article I just open the article in Firefox using my previously mentioned macro:
macro R set browser "firefox --new-tab about:reader?url=%u" ; open-in-browser ; set browser "`echo $BROWSER`"
Setting up the script
This is the script:
#!/usr/bin/env python3
from newspaper import Article
import sys
url = sys.argv[1]
a = Article(url)
a.download()
a.parse()
c = a.title.count("",1)
print(a.title)
print("="*c)
print("")
print(a.text)
For the script to work you need the Python-package called newspaper3k. Save the script, make it executable and then use it like this:
$ html2text.py <URL>
If you want decent folding of words and pagination I highly recommend you piping the output via the tools fold and less like this:
html2text.py %u | fold -s -w 115 | less
That’s it for now! I hope you liked my introductory post to Newsboat enough to give it a try.
Comments
There's no comments for this post. Use this e-mail form if you would like to leave a /public/ comment on this post. Or simply send me a private e-mail message if you have any feedback, or just want to say hello.